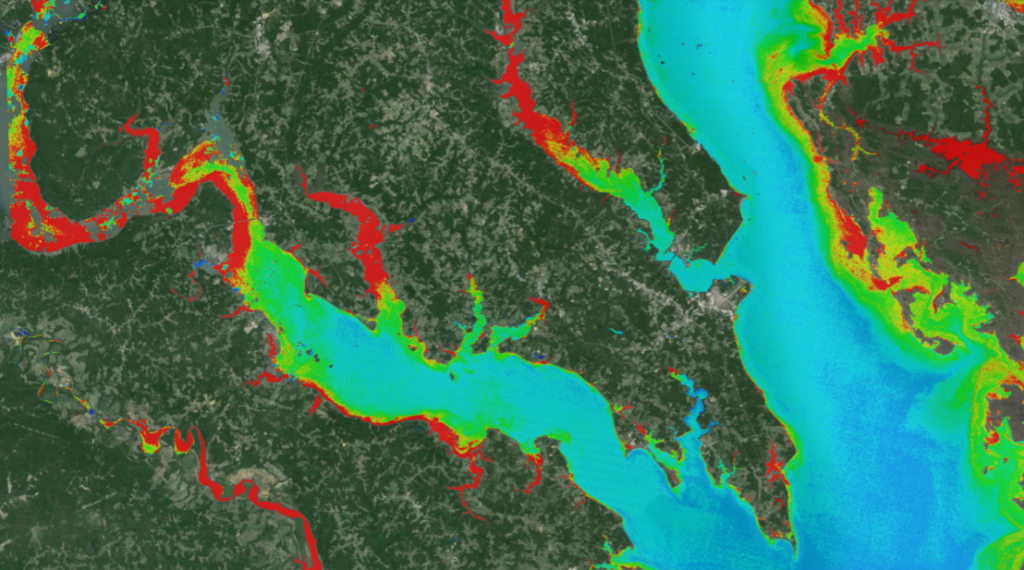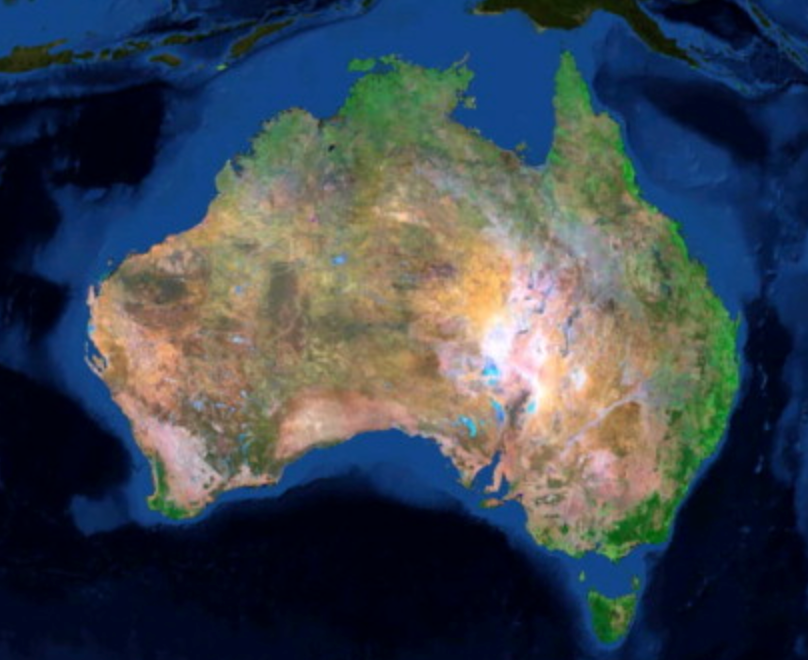
The multi-agency team behind the ULA project made sure that Landsat collected over time could be easily compared. The project uniformly processed Australia’s Landsat data holdings in terms of geometric and orthro-rectification, spectral calibration, surface reflectance calculations, cloud and cloud shadow masking, and fractional cover classification. The project also gridded the Landsat reflectance data into a product it calls the 25 m Australian Reflectance Grid (ARG25). ARG25 lets end users ask their science questions using Landsat data with the confidence that the surface reflectance measurements are consistent (reliably corrected for atmospheric effects). The implication of this is important: it means that scientists can use Landsat to answer questions related to their field of study and expertise, without having to also be an expert on atmospheric attenuation and Landsat sensor geometry.
The ARG25 product has already proved critical for monitoring crop and pasture conditions and accessing land management practices as well as the monitoring (and risk mitigation) of wind and water erosion across the country.
Australian policymakers are now looking to the ULA dataset—which has been recognized as a dataset of national significance—when making decisions regarding:
+ forestry management
+ surface water / flood impacts
+ crop management / food security
+ forest carbon inventories
+ coastal bathymetry
+ urban planning
As the authors explain:
“Earth Observation data acquired by the Landsat missions are of immense value to the global community and constitute the world’s longest continuous civilian Earth Observation program. However, because of the costs of data storage infrastructure these data have traditionally been stored in raw form on tape storage infrastructures which introduces a data retrieval and processing overhead that limits the efficiency of use of this data. As a consequence these data have become ‘dark data’ with only limited use in a piece-meal and labor intensive manner. The Unlocking the Landsat Archive project was set up in 2011 to address this issue and to help realize the true value and potential of these data.”
Reference: